In the
last post I wrote about how a biological neuron works, and in this post I'm going to write about perceptron and how to make one.
Basically the building block of our nervous system is the neuron which is the basic functional unit, it fires if it meets the threshold, and it will not fire if it doesn't meet the threshold. A perceptron is the same, you can call it the basic functional unit of a neural network. It takes an input, do some calculations and see if the output of reaches a threshold and fires accordingly.
 |
| A simple diagram of a perceptron it takes two inputs x1 and x2 do some calculations f and gives an output |
Perceptrons can only do basic classifications, these are called liner classifications it's like drawing a line and separating a set of data into two parts, it can't classify things the data into multiple classifications.
How a Perceptron Works
So the perceptron takes two inputs $x1$ and and $x2$, then they pass through the input nodes where they are multiplied by the respective weights. So the inputs $x1$ and $x2$ are like the stimulus to a neuron.
And you must not forget that these $x1$ and $x2$ should be numbers, because they are being multiplied by weights (numbers) so there should be a way to convert a text input to a number representations, which is a different topic.
The inputs to the perceptron are the inputs multiplied by their weights, where inside the perceptron all these weights are added together.
So adding them all together
$$\sum\ f = (x1 * w1)+(x2 * w2)$$
And this sum then passes through an activation function, there are many activation functions and the ones used commonly are the hyperbolic tangent and the sigmoid function.
In this example I am using the sigmoid function.
$$S(t) = \frac{1}{1 + e^{-t}}$$
So the output of the perceotron is what comes out through the activation function.
How Perceotrons Learn?
Like I said before the perceptrons learn by adjusting their weights until it meets a desired output. This is done by a method called
backpropagation.
In simple terms backpropagation is staring from calculating the error between the target and the output, and adjusting the weights backwards from the output weights, to hidden weights, to input weights (in a multilayered neural network).
In our simple perceptron it means adjusting the $w1$ and $w2$.
The equations and more details about backpropagation can be found here -
https://web.archive.org/web/20150317210621/https://www4.rgu.ac.uk/files/chapter3%20-%20bp.pdf
Let's Make a Perceptron.
So we are going to make a perceptron, this won't do much and will only act as an 'AND' or 'OR' gate. The design of the perceptron is as same as the image above. I am using NodeJs but this can be done in a simpler way using Python and Numpy which I will hopefully set up on my computer to future use.
Let's take the AND gate first, the truth table for the AND gate is,
$$x=0 | y = 0 | output = 0$$
$$x=1 | y = 0 | output = 0$$
$$x=0 | y = 1 | output = 0$$
$$x=1 | y = 1 | output = 1$$
We are giving the the two inputs $x$ and $y$ and we are calculating the difference between the desired output and the output through our perceptron which is the error and backpropagating and adjusting the weights until the error becomes very small.
This is called supervised learning.
So we are starting with two random values for the weights using
Math.random() and then passing our first set of data of the truth table, then we calculate the error and backpropagate and adjust the weights just once, and then we present the second set of data and backpropagate and adjust the weights once and third set of data and the fourth set of data and so on, and the cycle is repeated.
Make sure you
don't give the first set of data and adjust the weights till there is minimum error and then give the second set of data and adjust the weights till minimum error, this will not make the perceptron to learn all four patterns.
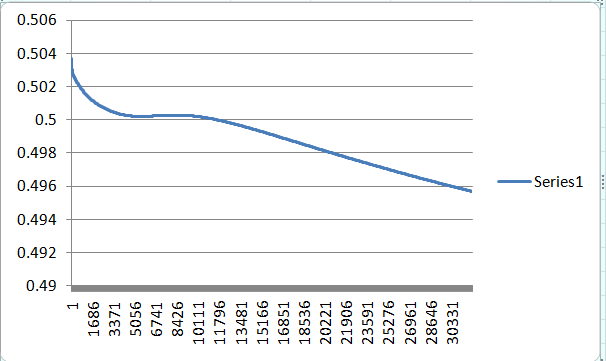
So I have repeated the cycle 10000 times and I plotted the error on a graph.
 |
| Error of 'and' gate changing over each time |
As you can see the error gets less and less and comes to a very low value, which is unnoticeable.
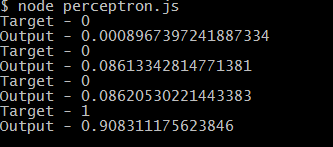
So now because the error is small means that the perceptron has been trained, so we an take that values of the weights, and feed the data of the truth table and see how close the perceptron's output is to the desired output.
 |
| Target and the output values of the perceotron in AND gate |
As you can see the perceptron has come pretty close to the target of the AND gate output.
We can do the same for the OR gate,
Starting with random values for weights and backpropagating like before until we get to the point of minimum error,
 |
| Error of 'or' gate changing over time |
And you can see that the OR gate perceptron has also come close to the desired target.
 |
| Target and output values of the perceptron in OR gate |
What about XOR?
$$x=0 | y = 0 | output = 0$$
$$x=1 | y = 0 | output = 1$$
$$x=0 | y = 1 | output = 1$$
$$x=1 | y = 1 | output = 0$$
You can see that the chart for the XOR is not as same as the ones we got for AND and OR gates, why is that?
 |
| Error of 'XOR' gate changing over time |
Also we can see that the output for the XOR gate is also not correct?
 |
| Target and output values of the perceptron in XOR gate |
So what is causing this error? Why can't the perceptron act as an XOR gate? how can we solve this? Hopefully I will answer that in a future post.
The code for the perceptron is available on here -
https://gist.github.com/rukshn/d4923e23d80697d2444d077eb1673e68
In the code you will see that there is a variable called bias, bias is not a must but it is good to add a bias, in a $y = mx + c$ bias is the $c$. In a chart without the $c$ the line goes through $(0,0)$ but $c$ helps you to shift where the line, the bias is also the same. We bass bias as a fixed input to the with it's own weight which we adjust just like another weight using backpropagation.
Also the $\eta$ is called the learning factor, you can change it adjust the speed of learning, a moderate value is better.