Yahoo came to a slow painful death few days back when majority of it was bought by Verizon for a lesser price than what Yahoo paid to by broadcast.com.
Like I said in a previous post Yahoo's problem was that it failed to innovate, failed to get along with the new trends in the tech arena unlike Facebook and Google who fiercely adopt to changes rather than just sticking in to what they are good at.
However when it comes to Twitter the once and still beloved micro-blogging platform ten years from now are we going to talk about Twitter the same way as we do today or are we going to talk about Twitter as same as we are talking about Yahoo?
Looking at Twitter it has lot of similarities to Yahoo. Yahoo did what they were good at and stuck with it, same can be said about Twitter. Over the past two to three years how much has Twitter changed? How much value has it added to their beloved users?
I see very little change from Twitter two years back and today, they added very little functionality and value to it's user experience. While the new kid on the block Snapchat has made inroads with their product. Snapchat has added stories, the discovery option where publishers can publish good content, recently they added memories. There is lot happening at Snapchat, what has happened on Twitter? Has it added any value to the users or advertisers?
Yes Twitter has added cards, and now every publication is using it, what good does it do? Where you have to scroll a long way down to see the same number of Tweets that we used to see without cards.
Also like Yahoo Twitter also made acquisitions like Vine and Periscope, which has yet to make a dent in the universe like they were supposed to do. And also Twitter has failed to address the harassment and bad experiences users face.
And all this has come down to less monthly active users, stunted growth, no clear path in making money.
There is lot at stake for Twitter and lot in common with Yahoo, it's up to them to change or like Google beat Yahoo it won't be long for Snapchat to replace Twitter.
Is Twitter The Next Yahoo
Tuesday, July 26, 2016
Who would have thought back then Yahoo will meet the sad end that they came across to they, being bought by Verizon for 4 billion dollars. They spent more money than that for their acquisitions, that they failed spectacularly.
Yahoo is a good example and teaches a lot for every company, no matter how strong you are, no matter how powerful you are, if you don't adapt, if you don't evolve you will be beaten by someone coming behind you. Even you are at the front of the race it's always good to look back where your competitors are.
Lack of innovation, missed opportunities, poor decision making, one can write a whole thesis about yahoo's failure.
Back in 1998 Google offered Yahoo their search platform, they didn't ask for much, just one million dollars. Yahoo rejected the offer, today Google is worth 500 billion dollars, and Yahoo was bought for hundred times less.
Yahoo didn't see or didn't want to adopt to the changing technological environment. They bought companies and screwed them up, I think Yahoo lacked a vision in what they want to be, a search engine? email platform? or a photo sharing service? They didn't have any idea, also they never had any idea in using big data or machine learning back in the day when others started using it.
That's my two cents on that, when I told this about to my mom her response was
Yahoo is a good example and teaches a lot for every company, no matter how strong you are, no matter how powerful you are, if you don't adapt, if you don't evolve you will be beaten by someone coming behind you. Even you are at the front of the race it's always good to look back where your competitors are.
Lack of innovation, missed opportunities, poor decision making, one can write a whole thesis about yahoo's failure.
Back in 1998 Google offered Yahoo their search platform, they didn't ask for much, just one million dollars. Yahoo rejected the offer, today Google is worth 500 billion dollars, and Yahoo was bought for hundred times less.
Yahoo didn't see or didn't want to adopt to the changing technological environment. They bought companies and screwed them up, I think Yahoo lacked a vision in what they want to be, a search engine? email platform? or a photo sharing service? They didn't have any idea, also they never had any idea in using big data or machine learning back in the day when others started using it.
That's my two cents on that, when I told this about to my mom her response was
If Yahoo bought Google back in the day maybe we won't even have a thing called Google
Monday, July 25, 2016
In my second post I wrote about perceptron and making a perceptron. And there I said that you can't make a XOR gate by using a perceptron, because a single perceptron can only do linearly separable problems. And XOR is not a linearly separable problem, so I thought of writing this post in how you can solve this.
I spent last couple of days, learning numpy and driving myself to insanity in how to make the two layer perceptron to solve the XOR gate problem. At one point I came to the verge of giving up, but the fun part of learning something by yourself not just in coding but anything is the feeling you get when you solve the problem, it's like finding a pot of gold at the end of the rainbow.
So how can you solve the XOR gate, it's by putting two input neurons, two hidden layer neurons and one output neuron all together using 5 neurons instead of just using one like we did it in the second post.
Although I call it a perceptron it's a miniature neural net itself, using backpropagation to learn. Just like what we did in the second post, we assign random values for the weights and we give the training data and the output, and we backpropagate until the error becomes minimum.
Few things that I learned the hard-way when making this was,
And because I was learning numpy at the same time, there were times I got things wrong when using the dot multiplication. There were times like I said before I didn't ran the inputs through the activation function, which gave me all sorts of bizarre charts.
So after further reading, trial and error, calculating everything by hand and after finding them and fixing them
Finally saw the light at the end of the tunnel, after correcting all the error, the error came
As you can see I had to run many rounds unlike the previous single perceptron which reached to a acceptable minimum error around 10000 rounds I had to run this nearly the 13000+ rounds to get to a point where there is a drop in error (total error) also the learning rate ( $\eta$ ) was far less this time 0.25 compared to 0.5 in the previous example, that's one reason for it to take long time to get the correct weights.
Also as the starting weights are assigned randomly the learning rounds needed to reach to a reasonably low error can vary.

Although I can only plot 32000 rows in excel the error reached to 0.001009 by the time it reached 100,000 learning rounds.
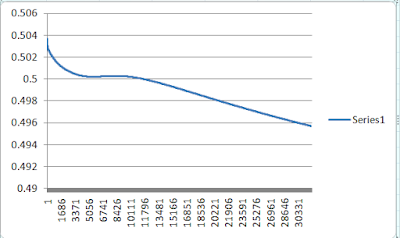
And like here, there are times where it will never learn, this is because the weights are assigned randomly at the beginning. Even after 100,000 rounds the error has only reached 0.487738646. This might be due to the network has hit a local minimum and might work if we continue training it or it will just never learn.
You will never know whether a neural network will learn or not and what makes neural networks unpredictable.
I know making a XOR perceotron is no big deal as machine learning is light years ahead now. But the what matters is making something by yourself, and learning something out of it and the joy that you get at the end of reaching the destination.
I did not add any bias to this example like the previous one because I was having a tough time making this without the bias, but it's better to have a bias and will add
The code is available here - https://gist.github.com/rukshn/361a54eaec0266167051d2705ea08a5f
I spent last couple of days, learning numpy and driving myself to insanity in how to make the two layer perceptron to solve the XOR gate problem. At one point I came to the verge of giving up, but the fun part of learning something by yourself not just in coding but anything is the feeling you get when you solve the problem, it's like finding a pot of gold at the end of the rainbow.
So how can you solve the XOR gate, it's by putting two input neurons, two hidden layer neurons and one output neuron all together using 5 neurons instead of just using one like we did it in the second post.
 |
| XOR perceptron structure |
Few things that I learned the hard-way when making this was,
- Every value should go through activation when they pass through a neuron, even the inputs should pass through an activation function when they pass through the $i1$ and $i2$ neurons in the diagram, it took me sometime to figure this out by myself.
- In my second post I have used the positive value at the sigmoid function not the negative value, if using the positive value at the sigmoid function then the changes are added to the existing weights, but if you are using the negative value at the sigmioid function then the weight changes are deducted, form the existing weights.
- You might have to run the learning process many rounds until you get to a point of acceptable error, because you might hit a local minimum where you can get close to the global minimum if you continue going through the training set.
- Also unlike in my second post it's better to calculate the total error, in the XOR there are four training sets, $[0,0],[0,1],[1,0],[1,1]$.
So you run through the four training sets, add the error at each training set. So you will be adding up four errors ( $\sum E = 1/2 * (target \tiny i$ $ - output \tiny i )$ ), and then save that total error to graph not plotting or taking error at each training set in to account.
And because I was learning numpy at the same time, there were times I got things wrong when using the dot multiplication. There were times like I said before I didn't ran the inputs through the activation function, which gave me all sorts of bizarre charts.
 |
| One bizarre chart I got when things were not going the right direction. |
So after further reading, trial and error, calculating everything by hand and after finding them and fixing them
 |
| Calculating it manually |
 | ||
| Error changing (total error) per each round |
As you can see I had to run many rounds unlike the previous single perceptron which reached to a acceptable minimum error around 10000 rounds I had to run this nearly the 13000+ rounds to get to a point where there is a drop in error (total error) also the learning rate ( $\eta$ ) was far less this time 0.25 compared to 0.5 in the previous example, that's one reason for it to take long time to get the correct weights.
Also as the starting weights are assigned randomly the learning rounds needed to reach to a reasonably low error can vary.

Although I can only plot 32000 rows in excel the error reached to 0.001009 by the time it reached 100,000 learning rounds.
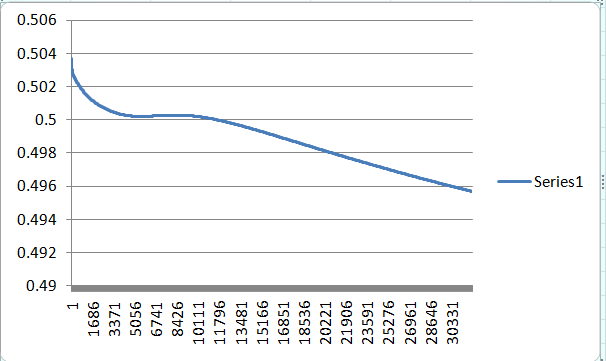
And like here, there are times where it will never learn, this is because the weights are assigned randomly at the beginning. Even after 100,000 rounds the error has only reached 0.487738646. This might be due to the network has hit a local minimum and might work if we continue training it or it will just never learn.
You will never know whether a neural network will learn or not and what makes neural networks unpredictable.
I know making a XOR perceotron is no big deal as machine learning is light years ahead now. But the what matters is making something by yourself, and learning something out of it and the joy that you get at the end of reaching the destination.
I did not add any bias to this example like the previous one because I was having a tough time making this without the bias, but it's better to have a bias and will add
The code is available here - https://gist.github.com/rukshn/361a54eaec0266167051d2705ea08a5f
Friday, July 22, 2016
In the last post I wrote about how a biological neuron works, and in this post I'm going to write about perceptron and how to make one.
Basically the building block of our nervous system is the neuron which is the basic functional unit, it fires if it meets the threshold, and it will not fire if it doesn't meet the threshold. A perceptron is the same, you can call it the basic functional unit of a neural network. It takes an input, do some calculations and see if the output of reaches a threshold and fires accordingly.
Perceptrons can only do basic classifications, these are called liner classifications it's like drawing a line and separating a set of data into two parts, it can't classify things the data into multiple classifications.
And you must not forget that these $x1$ and $x2$ should be numbers, because they are being multiplied by weights (numbers) so there should be a way to convert a text input to a number representations, which is a different topic.
The inputs to the perceptron are the inputs multiplied by their weights, where inside the perceptron all these weights are added together.
So adding them all together
$$\sum\ f = (x1 * w1)+(x2 * w2)$$
And this sum then passes through an activation function, there are many activation functions and the ones used commonly are the hyperbolic tangent and the sigmoid function.
In this example I am using the sigmoid function.
$$S(t) = \frac{1}{1 + e^{-t}}$$
So the output of the perceotron is what comes out through the activation function.
Like I said before the perceptrons learn by adjusting their weights until it meets a desired output. This is done by a method called backpropagation.
In simple terms backpropagation is staring from calculating the error between the target and the output, and adjusting the weights backwards from the output weights, to hidden weights, to input weights (in a multilayered neural network).
In our simple perceptron it means adjusting the $w1$ and $w2$.
The equations and more details about backpropagation can be found here - https://web.archive.org/web/20150317210621/https://www4.rgu.ac.uk/files/chapter3%20-%20bp.pdf
Let's take the AND gate first, the truth table for the AND gate is,
$$x=0 | y = 0 | output = 0$$
$$x=1 | y = 0 | output = 0$$
$$x=0 | y = 1 | output = 0$$
$$x=1 | y = 1 | output = 1$$
We are giving the the two inputs $x$ and $y$ and we are calculating the difference between the desired output and the output through our perceptron which is the error and backpropagating and adjusting the weights until the error becomes very small. This is called supervised learning.
So we are starting with two random values for the weights using Math.random() and then passing our first set of data of the truth table, then we calculate the error and backpropagate and adjust the weights just once, and then we present the second set of data and backpropagate and adjust the weights once and third set of data and the fourth set of data and so on, and the cycle is repeated.
Make sure you don't give the first set of data and adjust the weights till there is minimum error and then give the second set of data and adjust the weights till minimum error, this will not make the perceptron to learn all four patterns.
So I have repeated the cycle 10000 times and I plotted the error on a graph.
As you can see the error gets less and less and comes to a very low value, which is unnoticeable.
So now because the error is small means that the perceptron has been trained, so we an take that values of the weights, and feed the data of the truth table and see how close the perceptron's output is to the desired output.
As you can see the perceptron has come pretty close to the target of the AND gate output.
We can do the same for the OR gate,
Starting with random values for weights and backpropagating like before until we get to the point of minimum error,
And you can see that the OR gate perceptron has also come close to the desired target.
What about XOR?
$$x=0 | y = 0 | output = 0$$
$$x=1 | y = 0 | output = 1$$
$$x=0 | y = 1 | output = 1$$
$$x=1 | y = 1 | output = 0$$
You can see that the chart for the XOR is not as same as the ones we got for AND and OR gates, why is that?
So what is causing this error? Why can't the perceptron act as an XOR gate? how can we solve this? Hopefully I will answer that in a future post.
The code for the perceptron is available on here - https://gist.github.com/rukshn/d4923e23d80697d2444d077eb1673e68
In the code you will see that there is a variable called bias, bias is not a must but it is good to add a bias, in a $y = mx + c$ bias is the $c$. In a chart without the $c$ the line goes through $(0,0)$ but $c$ helps you to shift where the line, the bias is also the same. We bass bias as a fixed input to the with it's own weight which we adjust just like another weight using backpropagation.
Also the $\eta$ is called the learning factor, you can change it adjust the speed of learning, a moderate value is better.
Basically the building block of our nervous system is the neuron which is the basic functional unit, it fires if it meets the threshold, and it will not fire if it doesn't meet the threshold. A perceptron is the same, you can call it the basic functional unit of a neural network. It takes an input, do some calculations and see if the output of reaches a threshold and fires accordingly.
 |
| A simple diagram of a perceptron it takes two inputs x1 and x2 do some calculations f and gives an output |
How a Perceptron Works
So the perceptron takes two inputs $x1$ and and $x2$, then they pass through the input nodes where they are multiplied by the respective weights. So the inputs $x1$ and $x2$ are like the stimulus to a neuron.And you must not forget that these $x1$ and $x2$ should be numbers, because they are being multiplied by weights (numbers) so there should be a way to convert a text input to a number representations, which is a different topic.
The inputs to the perceptron are the inputs multiplied by their weights, where inside the perceptron all these weights are added together.
So adding them all together
$$\sum\ f = (x1 * w1)+(x2 * w2)$$
And this sum then passes through an activation function, there are many activation functions and the ones used commonly are the hyperbolic tangent and the sigmoid function.
In this example I am using the sigmoid function.
$$S(t) = \frac{1}{1 + e^{-t}}$$
So the output of the perceotron is what comes out through the activation function.
How Perceotrons Learn?
Like I said before the perceptrons learn by adjusting their weights until it meets a desired output. This is done by a method called backpropagation.
In simple terms backpropagation is staring from calculating the error between the target and the output, and adjusting the weights backwards from the output weights, to hidden weights, to input weights (in a multilayered neural network).
In our simple perceptron it means adjusting the $w1$ and $w2$.
The equations and more details about backpropagation can be found here - https://web.archive.org/web/20150317210621/https://www4.rgu.ac.uk/files/chapter3%20-%20bp.pdf
Let's Make a Perceptron.
So we are going to make a perceptron, this won't do much and will only act as an 'AND' or 'OR' gate. The design of the perceptron is as same as the image above. I am using NodeJs but this can be done in a simpler way using Python and Numpy which I will hopefully set up on my computer to future use.
Let's take the AND gate first, the truth table for the AND gate is,
$$x=0 | y = 0 | output = 0$$
$$x=1 | y = 0 | output = 0$$
$$x=0 | y = 1 | output = 0$$
$$x=1 | y = 1 | output = 1$$
We are giving the the two inputs $x$ and $y$ and we are calculating the difference between the desired output and the output through our perceptron which is the error and backpropagating and adjusting the weights until the error becomes very small. This is called supervised learning.
So we are starting with two random values for the weights using Math.random() and then passing our first set of data of the truth table, then we calculate the error and backpropagate and adjust the weights just once, and then we present the second set of data and backpropagate and adjust the weights once and third set of data and the fourth set of data and so on, and the cycle is repeated.
Make sure you don't give the first set of data and adjust the weights till there is minimum error and then give the second set of data and adjust the weights till minimum error, this will not make the perceptron to learn all four patterns.
So I have repeated the cycle 10000 times and I plotted the error on a graph.
 |
| Error of 'and' gate changing over each time |
So now because the error is small means that the perceptron has been trained, so we an take that values of the weights, and feed the data of the truth table and see how close the perceptron's output is to the desired output.
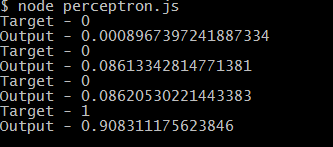 |
| Target and the output values of the perceotron in AND gate |
We can do the same for the OR gate,
Starting with random values for weights and backpropagating like before until we get to the point of minimum error,
 |
| Error of 'or' gate changing over time |
 |
| Target and output values of the perceptron in OR gate |
What about XOR?
$$x=0 | y = 0 | output = 0$$
$$x=1 | y = 0 | output = 1$$
$$x=0 | y = 1 | output = 1$$
$$x=1 | y = 1 | output = 0$$
You can see that the chart for the XOR is not as same as the ones we got for AND and OR gates, why is that?
 |
| Error of 'XOR' gate changing over time |
Also we can see that the output for the XOR gate is also not correct?
 |
| Target and output values of the perceptron in XOR gate |
The code for the perceptron is available on here - https://gist.github.com/rukshn/d4923e23d80697d2444d077eb1673e68
In the code you will see that there is a variable called bias, bias is not a must but it is good to add a bias, in a $y = mx + c$ bias is the $c$. In a chart without the $c$ the line goes through $(0,0)$ but $c$ helps you to shift where the line, the bias is also the same. We bass bias as a fixed input to the with it's own weight which we adjust just like another weight using backpropagation.
Also the $\eta$ is called the learning factor, you can change it adjust the speed of learning, a moderate value is better.
Tuesday, July 19, 2016
Perceptron is the basic unit of a neural network just like the neuron which is the building block of our nervous system. So before talking about artificial neural networks I thought of writing about some physiology that I learned at first year of medical college. The physiological mechanism of a real neuron.
The neuron is the building block of our nervous system, there are nearly hundred billion neurons inside the human brain, that is a lot of neurons. How does so many neurons fit inside our head? One reason is that our brain is not flat, it had bumps, and ridges which increase the surface area of the brain which will make room for many more neurons as opposed to the brain being a flat hemispherical object.
The Structure
Although the brain different kinds types of neurons specialized for different functions, the basic structure is the same. It has a cell body, which has the nucleus and from the cell body comes out dendrites which connects with adjacent neurons, these dendrites brings signals towards the neuron (cell body).
And from the cell body comes out a long process called the axon, this axon can be few centimeters in length, it end by splitting in to small processes called axon terminals, which connect to adjacent dendrites. So the axon carries signals away from the neuron coming from the cell body.
Each neuron connects with nearly a thousand adjacent neurons, that is nearly hundred billion multiplied by thousand connections inside our human brain.

The Function
The way neurons work is based on electricity, the neurons outside is positively charged and the inside is negatively charged, the voltage difference between them is called the resting potential. It is the neutral state of a neuron. The main reason that outside is more positive is due to more sodium on the outside of the cell than inside.
And along the membrane of the neuron we have sodium channels, and when a stimulation is received these channels which is closer to the stimulation are opened and sodium which is abounded on the outside comes inside the cell causing the voltage difference to rise (making the inside of the cell more positive than the outside) and as more and more sodium comes in the voltage difference become, this depends on the strength of the stimulus.
So if the voltage difference passes a certain threshold then the neuron fires, casing an impulse to be carried along the axon to the adjacent neurons stimulating the ones connected to them. If the stimulus is not strong enough then the threshold is not reached and the neuron doesn't fire. This goes on until a desired action occurs in the body.
So coming back to the neuron, once the voltage difference rise to a certain level then another type of channels open on the cell membrane, these are potassium channels which pumps potassium from inside of the cell to outside.
So as more and more potassium is pumped outside the voltage difference becomes less and less because potassium is also a positively charge ion. So the voltage difference comes to the level of resting potential and goes even beyond the resting potential and comes to a period called absolute refractory period. Which means during a small time period no matter how strong the new stimulation is, it is not going to fire, but after sometime the voltage difference comes back to the resting potential and the neuron is ready for a new stimulus. And this cycle repeats itself.

So like I said before there are nearly hundred billion to thousand connections in the human brain, so how does the brain recognize patterns? This depends on the pattern of which neurons get activated by reaching the threshold and which neurons do not. It's like binary 0,0,1,1,1,0,0....0 will represent one pattern and the next binary code will represent another. This these are the things that we learn since our childhood and gets hard-coded in to our brain.
This is just a simplified version of how brain works, the brain has different areas for different functions like a part for processing visual data, a different area for processing audio and different area for processing language etc. So the brain is a complex machine that we are yet to understand.
Friday, July 15, 2016
We take language for granted, we think that it is easy for us to understand something. If I ask your name it will only take a split second for you to come up with an answer, because we understands the question. What if you want a machine to understand a language as we do? Only then you will realize the complexity of understanding/language that we take for granted.
You can try this out, just do a simple search like 'tell me a good place to go out with my girlfriend in my city?' and you will realize that Google can't answer this question, not because they don't know my city or my location, if you do the search from the phone or if you are signed on to Google it knows your location and your city. It's that Google doesn't understand the meaning of the question, however if I ask the same question from a friend it won't take a second for him come up with an answer, because my friend understands the meaning behind the question, not Google.
A language is complex, words have different meanings, and same word can act as a verb and a noun depending on how you place it, and a language can have millions of words, so processing these words one at a time (brute forcing them) is impossible or too cumbersome.
Also the summery of two different states of a word can be the same, as an example 'dog' and 'dogs' both words mean the same thing, one is singular and other one is plural. However for a machine dog and dogs are two different words (dog != dogs). So if we are to tell a machine these similarities of words one at a time it will be still impossible or too much energy consuming work.
In a summery language is difficult to understand because
If we are to go through a vocabulary of words and find meanings and apply to a sentence it's brute forcing and will be highly ineffective.
But for some reason when we meet a word our mind just ticks and we get the meaning instantly or we understand a sentence as if there is a light bulb switching inside our brains, we don't go though a vocabulary of words it just happens. These days I am trying to learn German and using Duolingo to help me, and after going through the same German words few times the word and the meaning just sticks in my head. It's amazing how our brain process the data, I think there is a way that we are yet to understand how our brains process data. I don't know it because it is not taught at medical college, I don't know if anyone knows how our brains process data.
And although a computer can process data faster than a human, it is still not par with the understanding language, which means humans process language in a different way than computers, making it complex for machines to understand. I feel it's not that computers can't understand our language or our speech, its just that we don't know how to teach a machine to understand and process our language. And when we do lean how to teach them they will understand and process the language faster than humans.
Maybe emotions, past experiences may be playing a role in our light bulb effect in understanding the meaning, emotions and experiences are things that a computer doesn't have. May be if we can understand how our brains process language we might even be able to apply that to other computing problems and may even be able to speed up how our computers process data today.
I know the biological pathway in our brains that process language called the Wernicke's area, but what happens inside of that Wernicke's area is what we don't understand it's the place where all the magic happens.
It's fascinating to think how easy for us to understand a language and how we take it for granted everyday, but the difficulty to make a machine to understand a language or to teach how we understand a language.
You can try this out, just do a simple search like 'tell me a good place to go out with my girlfriend in my city?' and you will realize that Google can't answer this question, not because they don't know my city or my location, if you do the search from the phone or if you are signed on to Google it knows your location and your city. It's that Google doesn't understand the meaning of the question, however if I ask the same question from a friend it won't take a second for him come up with an answer, because my friend understands the meaning behind the question, not Google.
A language is complex, words have different meanings, and same word can act as a verb and a noun depending on how you place it, and a language can have millions of words, so processing these words one at a time (brute forcing them) is impossible or too cumbersome.
Also the summery of two different states of a word can be the same, as an example 'dog' and 'dogs' both words mean the same thing, one is singular and other one is plural. However for a machine dog and dogs are two different words (dog != dogs). So if we are to tell a machine these similarities of words one at a time it will be still impossible or too much energy consuming work.
In a summery language is difficult to understand because
- Language is ambiguous
- Language is productive
- Language is culturally specific
If we are to go through a vocabulary of words and find meanings and apply to a sentence it's brute forcing and will be highly ineffective.
It's a light bulb effect
But for some reason when we meet a word our mind just ticks and we get the meaning instantly or we understand a sentence as if there is a light bulb switching inside our brains, we don't go though a vocabulary of words it just happens. These days I am trying to learn German and using Duolingo to help me, and after going through the same German words few times the word and the meaning just sticks in my head. It's amazing how our brain process the data, I think there is a way that we are yet to understand how our brains process data. I don't know it because it is not taught at medical college, I don't know if anyone knows how our brains process data.
And although a computer can process data faster than a human, it is still not par with the understanding language, which means humans process language in a different way than computers, making it complex for machines to understand. I feel it's not that computers can't understand our language or our speech, its just that we don't know how to teach a machine to understand and process our language. And when we do lean how to teach them they will understand and process the language faster than humans.
Maybe emotions, past experiences may be playing a role in our light bulb effect in understanding the meaning, emotions and experiences are things that a computer doesn't have. May be if we can understand how our brains process language we might even be able to apply that to other computing problems and may even be able to speed up how our computers process data today.
I know the biological pathway in our brains that process language called the Wernicke's area, but what happens inside of that Wernicke's area is what we don't understand it's the place where all the magic happens.
It's fascinating to think how easy for us to understand a language and how we take it for granted everyday, but the difficulty to make a machine to understand a language or to teach how we understand a language.
Wednesday, July 13, 2016
Usually I post on my Medium blog but thought of posting it here because I thought it's going to be a long post and a boring reading for many others.
I was interested about machine learning for a long time and the recent hype got me interested about it all over again, and wanted learn more about it. I made a very simple neural network that can play ticktacktoe few months back and I thought about playing with image recognition but later I got bit interested about Natural Language Processing or NLP for short.
There are various methods out there, but I was interested in a way to pick out keywords from a sentence, specially from a question, which that keyword can be used to search for an answer.
The Problem
When we look at most questions what I felt was that there are only few words that are key to answering that questions, which are the keywords. If we can pick out that keyword finding an answer becomes simple it's about keyword spotting.
Let's say you are having a search engine or a website, that gives information about places and locations depending on the queries by a user, let's say the questions are like this,
So in question number one the keyword is 'avocado' in question number two the keyword is 'cocoa butter'. We don't need the words 'can', 'i', 'buy', 'find' to find an answer to the question that is being asked, we only need to know the word avocado and cocoa butter to know the answer to the question. That is what I thought about the simplest way to solve the problem, get the keyword solve the question.
The solution that I came up was giving weights to every word of the question, at the starting of it each word will have a value of 1, and the algorithm scans the sentence and looks for the keyword which we have given in the training set and after finding that keyword we add a 0.001 or some value like that to the keyword and we deduct 0.001 from all other words, and we save these words and the assigned weights in the vocabulary of the algorithm.
For example in the first question where can i buy avocado? the algorithm looks for the word avocado and adds 0.001 to it's current weight and we deduct 0.001 from all other words. Leaving us with just one word with a high weight than the rest of the words.
Then the algorithm moves to the second question, where can i find coca butter? but when come to second question the words 'where', 'can' are already in the vocabulary, with assigned weights (0.999) and here too in the second question just like before the answer is provided and a further 0.001 will be deducted from weights of the weights of the words like 'where', 'can', 'i' etc. And whatever the words that are not in the vocabulary and their weights are added.
This process is repeated for many many times, for many questions where we are left with very low weights for not so important weights and high values of weights for the important words (keywords).
And then it comes with a new word, 'bacon'. This word is given the default weight of 1 and added to the database, and the word with the highest weight is returned as the keyword, here it is bacon because it is a new word and has a weight of one, and other words have a lesser value than one.
So when the algorithm comes with a query that is similar to a one in the teaching set, 'where can i buy avocado?' the highest weighted word is 'avocado' and it is returned as the keyword. And the weights of the keyword and the other words are updated.
So in time the not so useful words like 'where' will have low weights and will get lower and where the keywords will get higher as time goes by. So more and more queries processed and better the algorithm becomes.
I know there are tools and existing methods of NLP but I was interested in making one from the ground up for fun. So what do you think? feel free to share what you think about it.
I was interested about machine learning for a long time and the recent hype got me interested about it all over again, and wanted learn more about it. I made a very simple neural network that can play ticktacktoe few months back and I thought about playing with image recognition but later I got bit interested about Natural Language Processing or NLP for short.
There are various methods out there, but I was interested in a way to pick out keywords from a sentence, specially from a question, which that keyword can be used to search for an answer.
The Problem
When we look at most questions what I felt was that there are only few words that are key to answering that questions, which are the keywords. If we can pick out that keyword finding an answer becomes simple it's about keyword spotting.
Let's say you are having a search engine or a website, that gives information about places and locations depending on the queries by a user, let's say the questions are like this,
- where can i buy avocado?
- where can i find coca butter?
So in question number one the keyword is 'avocado' in question number two the keyword is 'cocoa butter'. We don't need the words 'can', 'i', 'buy', 'find' to find an answer to the question that is being asked, we only need to know the word avocado and cocoa butter to know the answer to the question. That is what I thought about the simplest way to solve the problem, get the keyword solve the question.
The Solution
The first step was to find a set of questions to train the algorithm, which is readily available on sites like Twitter and Facebook. After that because we need to train the algorithm we will manually find the keywords of each question and manually feed the question and the answer to the algorithm.
The solution that I came up was giving weights to every word of the question, at the starting of it each word will have a value of 1, and the algorithm scans the sentence and looks for the keyword which we have given in the training set and after finding that keyword we add a 0.001 or some value like that to the keyword and we deduct 0.001 from all other words, and we save these words and the assigned weights in the vocabulary of the algorithm.
For example in the first question where can i buy avocado? the algorithm looks for the word avocado and adds 0.001 to it's current weight and we deduct 0.001 from all other words. Leaving us with just one word with a high weight than the rest of the words.
Then the algorithm moves to the second question, where can i find coca butter? but when come to second question the words 'where', 'can' are already in the vocabulary, with assigned weights (0.999) and here too in the second question just like before the answer is provided and a further 0.001 will be deducted from weights of the weights of the words like 'where', 'can', 'i' etc. And whatever the words that are not in the vocabulary and their weights are added.
This process is repeated for many many times, for many questions where we are left with very low weights for not so important weights and high values of weights for the important words (keywords).
So What Happens Next?
So after that we are giving a new question that is not in the training algorithm, like 'where can i buy bacon'. Here the algorithm comes up with words that it already knows like 'where', 'can', 'i', 'buy' these words are assigned low weights in the training set, it knows that these words are not important.
And then it comes with a new word, 'bacon'. This word is given the default weight of 1 and added to the database, and the word with the highest weight is returned as the keyword, here it is bacon because it is a new word and has a weight of one, and other words have a lesser value than one.
So when the algorithm comes with a query that is similar to a one in the teaching set, 'where can i buy avocado?' the highest weighted word is 'avocado' and it is returned as the keyword. And the weights of the keyword and the other words are updated.
So in time the not so useful words like 'where' will have low weights and will get lower and where the keywords will get higher as time goes by. So more and more queries processed and better the algorithm becomes.
The Glitch
This approach was good but I came across with some issues,
- Because the algorithm was checking for each word against a given vocabulary for it's weights it is like brute forcing and is not very efficient as vocabulary increases.
- If there is one word given in the search query and that will be the only word and will have the highest weight and will be returned as the query.
- If more than one word that are not in the vocabulary is present then both will have equal high values and will be returned as the keywords giving false results.
- The algorithm can only picks up one word, and can't pick up two related words. Such as Pizza Hut, if the search query contains the word 'Pizza Hut' then it will only return 'Pizza' not 'Pizza Hut' because the algorithm is only good at picking up one keyword not related phrases.
I know there are tools and existing methods of NLP but I was interested in making one from the ground up for fun. So what do you think? feel free to share what you think about it.
Subscribe to:
Comments
(
Atom
)